Very quick intro into SSG
SCAP Security Guide (or SSG for short) is the open source project to check out if you are interested in security policies. They provide fully automated SCAP content for various products ranging from Red Hat Enterprise Linux 5, 6, 7 all the way to JRE, Webmin, … The security policies are organized into hierarchical benchmarks. Each benchmark has a set of rules and each rule has:
- an automated check written in OVAL
- security community identifiers – CCE, CVE, NIST 800-53, …
- description, rationale, title, …
- bash fix snippet that can be run to put the machine in compliance with that particular rule
You can check out examples of these rules for RHEL7 in the Red Hat Enterprise Linux 7 security guides. Check out our Getting Started page for how to get started with SCAP security policies.
TL;DR: Give me the playbooks!
Here they are! Generated from SCAP Security Guide content for Red Hat Enterprise Linux 7: ssg-rhel7-ansible-examples.zip
cd /tmp mkdir ansible-ssg-test cd ansible-ssg-test wget https://martin.preisler.me/wp-content/uploads/2017/06/ssg-rhel7-ansible-examples.zip unzip ssg-rhel7-ansible-examples.zip cd ssg-rhel7-ansible-examples # check mode first sudo ansible-playbook --check ./ssg-rhel7-role-common.yml # this will change configuration of localhost! sudo ansible-playbook ./ssg-rhel7-role-common.yml
Fix scripts use-cases
It is possible to generate compliance bash scripts from any of the security policies and then run them on the machines to set them up. Recently we have added initial support for Ansible fixes. We envision that the user will be able to generate ansible playbooks in a similar way that they can generate bash remediation scripts today. We have two workflows in mind. Either the user scans the machine with OpenSCAP and then generates a “minimal” Ansible playbook from the results, this playbook will only contain fixes for rules that failed during evaluation. In the second use-case the user generates an Ansible playbook from the security policy. This playbook will contain fixes for all rules in that policy. Since the fixes are idempotent it is possible to apply the same playbook multiple times without detrimental effects to the configuration. We use the name “remediation roles” when we talk about remediation scripts for entire security policies.
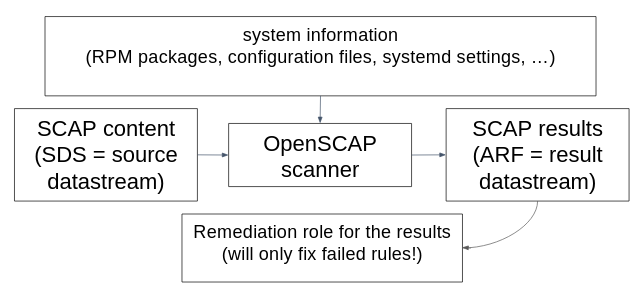
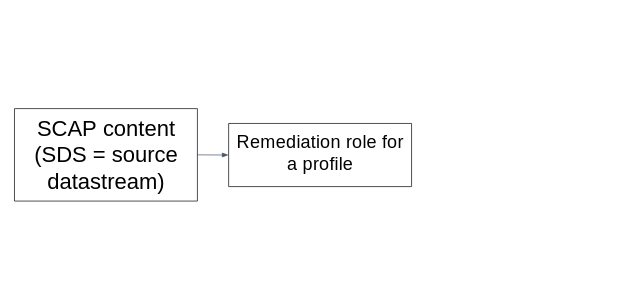
Remediation roles in SSG
We have added automated remediation role generators to the SCAP Security Guide build system. Every time the SSG SCAP content is built it will build a remediation role for every profile in every benchmark. We plan to include these remediation roles in the release ZIP file.
Example of a bash remediation role:
# The two fingerprints below are retrieved from https://access.redhat.com/security/team/key
readonly REDHAT_RELEASE_2_FINGERPRINT="567E 347A D004 4ADE 55BA 8A5F 199E 2F91 FD43 1D51"
readonly REDHAT_AUXILIARY_FINGERPRINT="43A6 E49C 4A38 F4BE 9ABF 2A53 4568 9C88 2FA6 58E0"
# Location of the key we would like to import (once it's integrity verified)
readonly REDHAT_RELEASE_KEY="/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release"
RPM_GPG_DIR_PERMS=$(stat -c %a "$(dirname "$REDHAT_RELEASE_KEY")")
# Verify /etc/pki/rpm-gpg directory permissions are safe
if [ "${RPM_GPG_DIR_PERMS}" -le "755" ]
then
# If they are safe, try to obtain fingerprints from the key file
# (to ensure there won't be e.g. CRC error).
IFS=$'\n' GPG_OUT=($(gpg --with-fingerprint "${REDHAT_RELEASE_KEY}" | grep 'Key fingerprint ='))
GPG_RESULT=$?
# No CRC error, safe to proceed
if [ "${GPG_RESULT}" -eq "0" ]
then
tr -s ' ' <<< "${GPG_OUT}" | grep -vE "${REDHAT_RELEASE_2_FINGERPRINT}|${REDHAT_AUXILIARY_FINGERPRINT}" || {
# If file doesn't contains any keys with unknown fingerprint, import it
rpm --import "${REDHAT_RELEASE_KEY}"
}
fi
fi
...
Example of an ansible remediation role:
---
# - hosts: localhost # set required host
tasks:
- name: "Read permission of GPG key directory"
stat:
path: /etc/pki/rpm-gpg/
register: gpg_key_directory_permission
check_mode: no
tags:
- ensure_redhat_gpgkey_installed
- high
- CCE-26957-1
# It should fail if it doesn't find any fingerprints in file - maybe file was not parsed well.
- name: "Read signatures in GPG key"
shell: "gpg --with-fingerprint '/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release' | grep 'Key fingerprint =' | tr -s ' ' | sed 's;.*= ;;g'"
changed_when: False
register: gpg_fingerprints
check_mode: no
tags:
- ensure_redhat_gpgkey_installed
- high
- CCE-26957-1
- name: "Set Fact: Valid fingerprints"
set_fact:
gpg_valid_fingerprints: ("567E 347A D004 4ADE 55BA 8A5F 199E 2F91 FD43 1D51" "43A6 E49C 4A38 F4BE 9ABF 2A53 4568 9C88 2FA6 58E0")
tags:
- ensure_redhat_gpgkey_installed
- high
- CCE-26957-1
- name: "Import RedHat GPG key"
rpm_key:
state: present
key: /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
when:
(gpg_key_directory_permission.stat.mode <= '0755')
and (( gpg_fingerprints.stdout_lines | difference(gpg_valid_fingerprints)) | length == 0)
and (gpg_fingerprints.stdout_lines | length > 0)
and (ansible_distribution == "RedHat")
tags:
- ensure_redhat_gpgkey_installed
- high
- CCE-26957-1
...
Current statistics, rule coverage
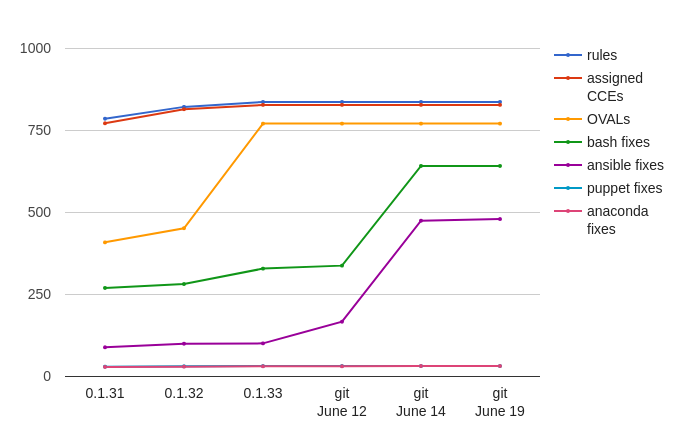
We are working to achieve better Ansible coverage. Our plan is to be on par with bash where possible. Let’s look at our progress.
As you can see we are very close to having Ansible remediations for 500 Red Hat Enterprise Linux 7 compliance rules. Our target is Bash remediation parity – 642 Ansible remediations.
Future plans, request for feedback
At this point we have a working prototype. We would appreciate feedback from Ansible power users. Are we following best practices? Do you see areas for improvements? If you are interested in helping us make Ansible a great tool for security compliance, let us know via our community channels!
Here are a few ansible playbooks generated from SSG commit f50a946a69ed2577f9a3b523a012acdc78a63efa: ssg-rhel7-ansible-examples.zip
Our plan is to iron out all the kinks and start submitting the roles into Ansible Galaxy. That way even users outside the OpenSCAP community will be able to discover them. Let us know what you think!